

BioINpro
(BioIN + Professional) : 전문가의 시각에서 집필한 보고서 제공보건의료 데이터 비식별화 : 문제점과 대안
- 등록일2018-03-27
- 조회수15496
- 분류레드바이오 > 의료서비스기술, 레드바이오 > 보건・간호기술
-
저자/소속
신수용 조교수/ 삼성융합의과학원 디지털헬스학과
-
발간일
2018-03-27
-
키워드
#보건의료#데이터#비식별화
- 첨부파일
- 차트+ ? 차트+ 도움말
 보건의료 데이터 비식별화 - 문제점과 대안.pdf
보건의료 데이터 비식별화 - 문제점과 대안.pdf
 보건의료 데이터 비식별화 가이드라인 및 표준문서
보건의료 데이터 비식별화 가이드라인 및 표준문서
 비식별화 정도와 정보의 유용성 관계
비식별화 정도와 정보의 유용성 관계

1. 개요
보건의료 분야에서도 빅데이터의 가치가 높이 인정받고 있으며,1), 보건의료 빅데이터의 활용은 보건의료 질 향상과 서비스 개선에 큰 역할을 할 것으로 기대되고 있다. 특히 최근 비약적인 발전을 보이고 있는 인공지능 기술과 결합하여 질병 진단, 예후 예측, 신약 개발 등에서 이미 많은 성과를 보이고 있다. 2)
그런데, 보건의료 데이터 활용을 위해서는 개인으로부터 명시적인 개별 동의서를 획득하거나, 비식별화를 통해 개인을 알아볼 수 있는 개인식별정보를 제거하는 두 가지 방법이 있다. 빅데이터의 관점에서 보면 아주 많은 사람들의 의료 및 건강 관련 정보들을 활용해야 한다는 점에서, 개개인으로부터 일일이 동의서를 획득하는 것은 비용과 시간을 너무 많이 필요로 한다. 따라서 보건의료 빅데이터 활용에서는 비식별화된 데이터를 사용하는 것이 일반적인 방법이다. 하지만 국내에서는 현재 비식별화에 대한 법·제도적 근거가 미흡하여 많은 논란이 있다.
본 글에서는 보건의료 데이터 비식별화에 한정하여, 우선 현행 개인정보 비식별 조치 가이드라인 및 관련 법령의 문제점을 집어보고, 외국의 사례를 소개한 이후 현재의 문제점을 극복할 수 있는 대안에 대해서 살펴보고자 한다.
----------------------------------------------------------------------------------------
1) 2013년 맥킨지 보고서에 의하면 미국에서만 보건의료 빅데이터 활용을 통해 1,900억 달러를 절감할 수 있을 것으로 예측하였으며, 2017년 Market&Market의 보고서에 의하면 2022년 보건의료 빅데이터 분석 시장은 289억 달러에 달할 것으로 예측되고 있다.
2) 2016년 미국의학회지에 발표된 당뇨병성 망막변증 진단, 2017년 네이처에 발표된 피부암 진단, 2017년 12월에 미국의학회지에 발표된 유방암 진단 및 당뇨에 기인한 안과질환 진단 등
2. 개인정보 비식별 조치 가이드라인
2016년 6월에 국무조종실 주도로 관련부처들(행정자치부, 미래창조과학부, 보건복지부, 방송통신위원회, 금융위원회)이 협의를 하여 관계부처 합동으로 “개인정보 비식별 조치 가이드라인”을 발표하여, 비식별화에 대한 방법을 구체적으로 제시하였다.
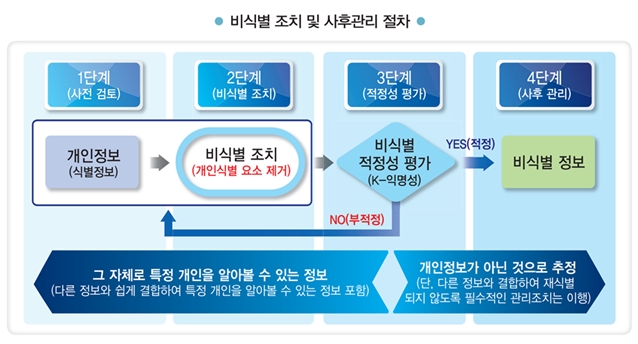
[그림 1] 개인정보 비식별 조치 가이드라인 요약
해당 가이드라인은 크게 4단계로 구성되어 있다. 1단계는 “사전 검토”단계로 기관이 자율적으로 개인식별정보를 정의한다. 2단계에서는 “비식별 조치”단계로 현재 널리 사용되고 있는 다양한 비식별화 기법3)을 적절히 사용하여 개인식별정보를 제거하는 과정이다. 3단계는 1, 2단계에서 수행한 결과물인 비식별 자료가 적정하게 생성되었는지 평가하는 “적정성 평가”단계이다. 이전 단계에서 기관의 자율성을 보장한 만큼 3단계에서는 엄격한 기준을 제시하고 있다. 외부전문가가 과반수이상인 평가단을 구성하여야 하며, 외부전문가는 각 산업분야별 비식별화 전문기관4)에서 관리하는 전문가 풀에서 법률 전문가, 비식별 조치 기법 전문가를 각 1명 이상씩 활용하도록 강제하고 있다. 또한 여러 기밀성 모델(confidentiality model) 중에서 k-익명성5)을 반드시 사용하도록 제시하였다. 마지막 4단계는 “사후 관리”단계로 적정성 평가를 통과했더라도 주기적으로 비식별화된 데이터에 대해서 적절한 관리적·기술적 정보보호 조치 및 재식별 가능성에 대해서 감시하도록 하고 있다.
----------------------------------------------------------------------------------------
3) 가명처리, 총계처리, 데이터 삭제, 데이터 범주화, 데이터 마스킹 등이 대표적인 방법으로 가이드라인에 소개되어 있다.
4) 보건복지부 비식별화 전문기관은 사회보장정보원이 선정되었고, 2018년 현재 전문가 인력풀이 구성되어 있다.
5) k-익명성은 쉽게 말해, 전체 데이터 집합에서 반드시 k개 이상 동일한 데이터가 존재해야지만 익명성이 보장된다는 개념이다.
그밖에 가이드라인에서 주목할 만한 내용들은 개인정보 보호법에 명시된 “통계작성 및 학술연구를 위해 개인을 식별할 수 없는 형태로 가공된 정보”6)는 3단계인 적정성 평가를 제외할 수 있다는 것과 민감정보인 건강정보 및 유전정보의 경우에는 해당 특별법인 생명윤리 및 안전에 관한 법률(생명윤리법)도 준수하도록 권고하고 있는 점이다.
3. 국내 법·제도의 문제점
가. 개인정보 보호법
개인정보 보호법은 개인정보 보호와 관련된 기본법이기 때문에 개인식별정보 비식별화와 관련된 사항도 우선적으로 동법의 조항을 먼저 살펴보아야 한다. 앞에서 소개한 가이드라인의 상위법도 당연히 개인정보 보호법이다.
그런데, 개인정보 보호법의 가장 큰 문제점은 용어의 모호성과 포괄성에 있다. 개인정보 보호법은 일단 개인정보를 “살아 있는 개인에 관한 정보로서 성명, 주민등록번호 및 영상 등을 통하여 개인을 알아볼 수 있는 정보(해당 정보만으로는 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합하여 알아볼 수 있는 것을 포함한다)”이라고 정의되어 있다.7) 즉 개인정보 보호법에서는 개인정보(personal information)가 개인을 식별할 수 있는 정보, 즉 개인식별정보(personally identifiable information)를 의미하고 있다. 또한 개인식별정보 중에서도 직접 식별자(direct identifier)와8) 간접 식별자(indirect identifier)9)을 모두 포함하고 있는데, 개인정보와 다른 의미를 가지는 개인식별정보를 “개인정보”라고 정의하면서 혼란을 유발시키고 있다.
----------------------------------------------------------------------------------------
6) 개인정보 보호법 제18조제2항제4호
7) 개인정보 보호법 제2조제1항
8) 단독으로 “개인을 알아볼 수 있는 정보”
9)“해당 정보만으로는 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합하여 알아볼 수 있는 것”
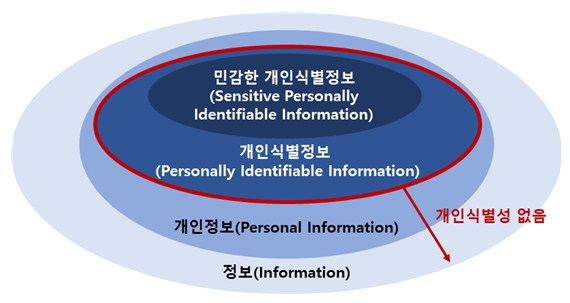
[그림 2] 개인정보와 개인식별정보의 차이점
그림으로 설명한 것처럼 일반적인 정보가 있고, 정보 중에서 개인에 관한 정보인 개인정보가 있으며, 개인정보 중에서 개인을 식별할 수 있는 개인식별정보가 있다. 예를 들어 키, 몸무게는 개인정보이지만 개인을 식별할 수는 없기 때문에 개인식별정보는 아니다. 그러나 일반적인 인식으로는 키, 몸무게는 개인정보이기 때문에 개인 식별성이 없다는 이유로 개인의 동의 없이 사용하겠다고 한다면 많은 반발이 생길 수밖에 없다. 또한 개인정보 보호법에서는 “건강 정보 및 유전자검사 등의 결과로 얻어진 유전정보10)”을 민감정보로 개인정보 중에서도 특별히 보호받아야 하는 정보로 정의하고 있다. 여기서도 모순이 발생하는데, 키, 몸무게는 건강과 관련된 정보이기 때문에 민감정보이나, 개인 식별성이 없다. 즉, 법적 정의가 기술적 정의와 맞지 않아서 실제로 비식별화를 할 때 많은 문제점을 불러일으키게 된다.
----------------------------------------------------------------------------------------
10) 개인정보 보호법 제23조, 동법 시행령 제18조
그리고 개인정보 보호법에서는 간접식별자를 정의하면서 “다른 정보와 쉽게 결합”이라는 모호한 표현을 쓰고 있다. 물론 가이드라인에서 해당 문구에 대한 설명으로 “결합 대상이 될 다른 정보의 입수 가능성이 있어야 하고, 또 다른 정보와의 결합 가능성이 높아야 함”이라고 설명하고 있다. 보다 상세히는 “합법적으로 정보를 수집할 수 없거나 결합을 위해 불합리한 정도의 시간과 비용이 필요한 경우라면 쉽게 결합할 수 있는 상태라고 볼 수 없다”고 명시하고 있다. 하지만 이런 설명도 역시나 보건의료 데이터에서는 명확하지 않다. 예를 들어 많은 경우, 의사들은 자기 환자들은 비식별화 하더라도 쉽게 알아볼 수 있다고 이야기를 하고, 실제로 그런 경우가 발생할 수 있다. 이런 경우에 대한 해결책은 전혀 제시하고 있지 않다.
개인정보 보호법에서의 또 다른 문제점은 비식별, 재식별(re-identification) 등 필수적인 용어를 전혀 정의하고 있지 않다는 점이다. 개인정보 보호법에는 비식별에 해당하는 용어가 전혀 등장하지 않으며, 단지 앞에서 소개한 것처럼 “특정 개인을 알아 볼 수 없는 형태”라는 표현만 등장할 뿐이다. 이로 인해 비식별화, 익명화, 가명화 등 조금씩 다른 의미를 가진 용어들이 혼재되어 사용되고 있다. 그리고 불행이도 재식별에 대한 설명은 전혀 등장하지 않는다. 이로 인해 사람마다 다르게 해석을 하고 있다. 일부에서는 개인의 직접식별자(이름, 주소, 전화번호 등)를 밝혀내는 것이라고 이야기하고, 다른 쪽에서는 서로 다른 데이터베이스에서 누구인지는 모르나 동일한 사람이라는 것을 확인하는 것도 재식별이라고 주장을 하고 있다. EU의 GDPR (General Data Protection Regulation)처럼 용어부터 명확히 정의11)를 해야지 보다 건설적인 논의가 가능할 것이다.
----------------------------------------------------------------------------------------
11) https://iapp.org/media/pdf/resource_center/PA_WP2-Anonymous-pseudonymous-comparison.pdf
나. 비식별 조치 가이드라인
가이드라인의 법적 효력은 논외로 하더라도, 현재 가이드라인은 보건의료 데이터에 적용하기에는 많은 문제점을 가지고 있다. 첫째, 가이드라인은 정형데이터에 대한 방법만을 제시하고 있다. 보건의료 데이터는 대부분의 데이터들이 비정형데이터(텍스트, 이미지, 영상 등)인 상황에서 이에 대한 보완이 반드시 필요하다.
둘째, 보건의료 데이터는 가이드라인에서 필수요소로 제시한 k-익명성을 준수하는 것이 불가능하다는 점이다. 보건의료 데이터는 다른 산업 군들의 데이터들과 다르게 데이터가 증가하면 데이터의 항목도 같이 증가한다는 특이한 성질을 가지고 있다. 예를 들어 환자들이 계속 병원에 방문하게 되면 새로운 검사를 추가하게 되고, 상황에 맞는 새로운 치료법(약, 처치, 수술 등)을 적용하기 때문에 항목이 고정되지 않는다는 특징이 있다. 또한 초기에 항목을 고정하더라도 보건의료 연구를 위해서는 필요로 하는 항목의 수가 아주 많기 때문에 최소한 수십 개, 많게는 수백 개의 항목을 수집해야 한다. 이러한 경우에 k-익명성을 준수하기 위해서 각 항목을 군집화하게 되면 데이터의 활용도가 사라져 버린다. 가이드라인에서는 단순한 진단명, 연령, 성별 등에 대해서 k-익명성이 적용된 사례를 보여주고 있는데, 실제 연구를 위해서는 각 검사들의 결과값이 필요한데, 그렇게 되면 검사 결과값들이 전부 군집화되어12) 전혀 연구에 활용할 수 없게 된다. 항목이 5개만 되더라도 5-익명성을 지키기 위해서 모든 데이터들이 왜곡되어 버린다.13) 필요로 하는 검사들이 많아서 항목이 늘어나게 되면 갈수록 더 쓸모없는 데이터들만 생성이 된다. 특히 최근에 딥러닝을 통해서 활발히 연구되고 있는 의료영상의 경우 모든 환자들의 개별 영상은 서로 다르다. 따라서 의료 영상에 대해서는 k-익명성을 도입하는 것은 불가능하다. 현재 가이드라인은 평가의 편의성을 위해서 k-익명성을 도입하였는데, 가이드라인에서도 k-익명성의 한계 때문에 보완책14)을 제시하고 있다. 이는 k-익명성은 개발된 지 오래된 기법으로 한계가 명확하기 때문이다.
셋째, 가이드라인은 재식별화가 필요한 상황을 전혀 고려하고 있지 않다. 보건의료 연구의 경우 비식별화된 데이터를 사용하다가도 재식별을 해야 하는 상황이 발생할 수 있다. 예를 들어, 비식별 환자 데이터 중에서 특정 임상 시험에 필요한 환자를 발견하여 임상 시험에 참여시키고자 하는 경우이거나, 후속 연구를 위해 추가적인 환자의 개인 정보 획득이 필요한 경우 등이다. 이 경우 전부 동의서를 획득하기 위해서는 환자의 개인식별정보를 알아내는 것이 반드시 필요하다. 이런 경우를 위해서 연구자가 임의로 재식별화하는 것이 아니라 공식적인 재식별 절차를 명시하는 것이 필요하다. 생명윤리법에 의하면 해당 업무는 시행규칙에 “익명화 해지 등에 관한 사항”으로 명시되어 있다.15)
넷째, 보건의료 분야에서 새롭게 등장하고 있는 개인식별정보에 대한 고려가 없다. 현행 가이드라인에서도 단지 보건의료 분야 데이터의 경우 관련 법률을 따르라고만 명시되어 있을 뿐이다. 현재 가장 문제시되는 정보는 유전체 정보이다. 영국 PHG Foundation에서 2017년 12월에 발표한 “Identification and genomic data”라는 문서에 문제점이 잘 설명되어 있다.16) 일반적으로 유전체 데이터라고 통칭을 하나, 유전체 데이터는 세부적으로 DNA 서열 전체 혹은 일부분 (exome 영역 등) 일수도 있고, 발견된 유전 변이 일수도 있다. 각각은 서로 다른 성격의 데이터이기 때문에 구분을 해야 한다. 또한 유전체 데이터의 경우 활용되는 상황(context)에 따라서 개인 식별성을 가질 수도 있고, 없을 수도 있다. 예를 들어 해당 환자의 진료 정보와 결합해서 사용될 경우에는 식별성이 크지만, 유전체 서열만으로는 식별성이 전혀 없다. 유전체 서열이 식별성을 가진다고 생각하는 경우가 많은데, 이는 비교 대상 (범죄자 DNA 데이터베이스 혹은 친자 확인의 경우 부모 DNA 등)이 있어야만 식별성이 가지게 된다. 해당 문서에서도 유전체 정보 그 자체는 본질적으로 식별성을 가지지 않으나, 다양한 연결성을 가지기 때문에 조심해야 한다고 언급하고 있다. 이런 논의는 기관에 맡겨둘 것이 아니라 정부 차원에서 논의를 해서 명확한 기준을 제시해야 한다.
----------------------------------------------------------------------------------------
12) 예를 들어, 실제 당화혈색소 수치가 아닌, 정상/비정상으로 구분해야만 한다.
13) 실제 예제는 Soo-Yong Shin, “Issues and Solutions of Healthcare Data De-identification: The Case of South Korea,” Journal of Korean Medical Science 33 (2018): e41.의 Table 1과 2에 제시되어 있다.
14) l-다양성, t-근접성 등을 제시하고 있으며, 실제 평가에서 l-다양성 까지는 확인하고 있는 추세이다.
15) 생명윤리 및 안전에 관한 법률 시행규칙 제42조제2항제4호
16) http://www.phgfoundation.org/documents/PHGF-Identification-and-genomic-data.pdf
4. 외국 보건의료 데이터 비식별화 가이드라인
전 세계적으로 다양한 비식별화 가이드라인 및 국제표준들이 최근 발표되었는데, 이는 세계 각국에서도 큰 논란이 되고 있다는 것을 반증한다. 다만 보건의료 데이터 비식별화에 한정한 가이드라인은 많지 않다. 유럽 식약처(European Medicines Agency), 미국 학술원(National Academies of Sciences, Engineering, and Medicine), 미국 보건부 등에서 발표한 가이드라인이 대표적이다.
[표 1] 보건의료 데이터 비식별화 가이드라인 및 표준문서
국가 | 기관 | 문서 | 발표일시 |
영국 | Information Commissioner’s Office | Anonymisation: managing data protection risk code of practice17) | 2012.11 |
UK Anonymization Network | The anonymisation decision-making framework18) | 2016 | |
EU | European Medicines Agency | European medicines agency policy on publication of clinical data for medical products for human use19 | 2014.10 |
캐나다 | Information and Privacy Commissioner of Ontario | De-identification guideline for structured data20) | 2016.6 |
Council of Canadian Academies | Assessing Health and Health-related Data in Canada21) | 2015 | |
일본 | Ministry of Health, Labour and Welfare | Provision of Anonymized Data22) | 2017.3 |
미국 | National Institute of Standards and Technology | NIST SP 800-188: De-identification government dataset23) | 2016.12 |
Health Information Trust Alliance | De-identification Framework24) | 2016.4 | |
National Institute of Standards and Technology | NISIR 8053: De-Identification of Personal Information25) | 2015.10 | |
National Academies of Sciences, Engineering, and Medicine | Sharing clinical trial data26) | 2015.1 | |
IHE (Integrating the Healthcare Enterprise) | IHE IT Infrastructure Handbook: De-identification27) | 2014.3 | |
Department of Health and Human Service | Guidance regarding methods for de-identification of protected health information in accordance with the Health Insurance Portability and Accountability (HIPAA) Privacy Rule28) | 2012.11 | |
호주 | Australian National Data Service | ANDS Guide: De-identification29) | 2017.1 |
싱가포르 | Personal Data Protection Commission | Guide to Basic Data Anonymisation Techniques30) | 2018.1 |
ISO (International Organization for Standardization) | ISO/TS 25237 Health informatics - Pseudonymization31) | 2017.01 (개정) | |
ISO/IEC DIS 20889 Information technology - Security techniques - Privacy enhancing data de-identification techniques32) | (개발중) | ||
----------------------------------------------------------------------------------------
17) https://ico.org.uk/media/1061/anonymisation-code.pdf
18) http://ukanon.net/wp-content/uploads/2015/05/The-Anonymisation-Decision-making-Framework.pdf
19) http://www.ema.europa.eu/docs/en_GB/document_library/Other/2014/10/WC500174796.pdf
20) https://www.ipc.on.ca/resource/de-identification-guidelines-for-structured-data/
21) http://www.scienceadvice.ca/en/assessments/completed/health-data.aspx
22) http://www.mhlw.go.jp/english/database/anonymized_data/index.html
23) https://csrc.nist.gov/csrc/media/publications/sp/800-188/archive/2016-08-25/documents/sp800_188_draft.pdf
24) https://hitrustalliance.net/de-identification/
25) http://nvlpubs.nist.gov/nistpubs/ir/2015/NIST.IR.8053.pdf
26) http://nationalacademies.org/HMD/Reports/2015/Sharing-Clinical-Trial-Data.aspx
27) http://ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_Handbook_De-Identification_Rev1.0_2014-03-14.pdf
28) https://www.hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification/index.html
29) https://www.ands.org.au/__data/assets/pdf_file/0003/737211/De-identification.pdf
30) https://www.pdpc.gov.sg/-/media/Files/PDPC/PDF-Files/Other-Guides/Guide-to-Anonymisation_v1-(250118).pdf
31) https://www.iso.org/standard/63553.html
32) https://www.iso.org/standard/69373.html
이 중에서도 미국 보건부에서 발표한 비식별화 가이드라인 (HIPAA 비식별화 가이드라인)을 현행 비식별 조치 가이드라인을 작성할 때 많이 준용한 것으로 보여 간략히 설명한다. HIPAA 비식별화 가이드라인은 2012년 11월에 발표되었으며, HIPAA에서 정의한 18개의 PHI (Protected Health Information)에 대해서 전문가 판단 방법(Expert Determination Method)나 완전히 제거하는 방법(Safe Harbour method)를 제시하고 있다. 현실적으로 100% 완전히 제거하는 방법은 불가능하기 때문에 대부분은 전문가 판단 방법을 사용하고 있는데, 국내 가이드라인과 달리 재식별 위험도의 기준도 전문가의 판단에 맡기도록 하고 있다. 다만 HIPAA 비식별화 가이드라인의 한계는 18개 외의 개인식별정보는 명시적으로 고려하지 않는다는 점이다.
그 외 대부분의 가이드라인들과 국내 가이드라인의 차이점은 k-익명성같은 특정 기법을 한정하지 않고, 주어진 데이터에 적합한 위험도 분석 기법(risk-based analysis)을 통해 재식별 위험을 판단하도록 하고 있다는 점이다.
...................(계속)
* 로그인 하셔야 자세한 정보를 모두 보실 수 있습니다.
지식
동향