

기술동향
강화학습 연구 및 융합 기술 동향
- 등록일2021-03-31
- 조회수7218
- 분류기술동향 > 종합 > 종합
-
자료발간일
2021-03-31
-
출처
정보통신기획평가원
- 원문링크
-
키워드
#강화학습#융합기술#융합기술동향
- 첨부파일
 file152989681938878367-199002.pdf
file152989681938878367-199002.pdf
강화학습 연구 및 융합 기술 동향
◈목차
I. 서론
Ⅱ. 비지도 강화학습
Ⅲ. 비지도 강화학습 응용분야
Ⅳ. 결론
◈본문
I. 서론
강화학습(Reinforcement Learning)은 MDP(Markov Decision Process) 기반의 최적화 개념과 동물심리학 개념(trial-and-)을 결합한 인공지능 기반 기계학습 알고리
즘 중 하나이며,시스템 최적화 문제를 풀기 위해 많은 연구 및 개발이 이루어지고 있다.
또한,강화학습은 모든 시스템 환경 정보를 담당하고 관여하는 시물레이션 혹은 시스템환경(Environment)을 중심으로 에이전트(Agent)가 환경에서 파생되는 데이터를 이용하
여 보상함수(Reward Function)를 구성하고 이를 반복적으로 개선하여 최적의 목표를 달성하는 시스템 제어 방법이다. 이를 위해서 에이전트는 환경으로부터 파생되는 복수의
환경 상태(State) 변화,에이전트의 행동(Action) 제어,시스템 보상함수 설계,정책 (Policy) 개선 및 최적화(Optimization) 모델 도출이라는 유기적인 프로세스를 진행하여
야 하며,이에 따른 환경 상태 정의,행동 결정,보상함수 및 정책 설계 등의 학습 지표들이 잘 맞물려서 작동해야 좋은 학습 효과를 얻을 수 있다.
강화학습은 다른 기계학습 알고리즘과는 달리 에이전트의 행동에 따른 보상 학습을 기반으로 시스템 제어를 달성하는 최적 제어 솔루션이기 때문에,보상함수를 설계하기 위한
사용자(엔지니어)의 노력이 매우 중요하며,시스템/시물레이션 환경에서 파생되는 데이터를 기반으로 학습 프로세스를 진행해야 하므로 시스템/시물레이션 환경이 반드시 존재해
야 하는 제약 사항이 있어 다양한 분야에 적용하여 폭넓게 발전하기에는 여전히 한계가 있다.
하지만,2013년 심층신경망(Deep Neural Network: DNN)을 결합한 심층 강화학습(Deep Reinforcement Learning) 방법이 도래하면서 학습을 위한 다양한 라이브러리
(Library)들이 제공되어 수많은 학습 데이터를 처리하기 위한 리소스 문제점들이 해결되고 있으며,실험 및 검증을 위한 많은 가상 시물레이션 환경들이 제공되어 강화학습 기반
최적 제어 문제를 풀기 위해 다양한 솔루션들과 함께 빠르게 발전해 나아가고 있다.
또한,강화학습은 2015년 2월 네이처에 게재된 DQN(Deep Q_Network) 알고리즘으로 인해 학습 패러다임이 바뀌는 현상들이 본격적으로 나타나기 시작했다. 기존 강화학습
은 학습 환경의 상태와 행동을 통해 출력되는 기댓값을 예측하는 방법으로 의사결정을 위한 Q 함수(Q-function)와 정책을 유기적으로 학습 개선하여 최적 제어를 달성하는
방법이다.
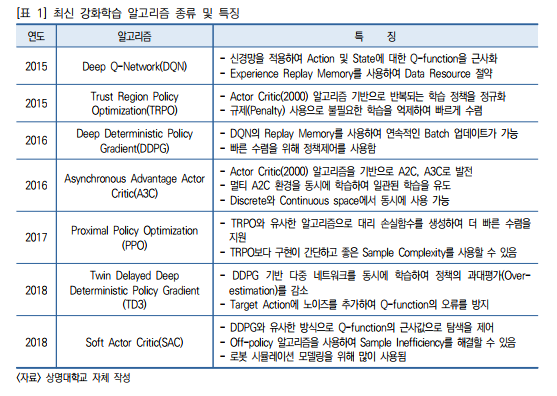
하지만 기존의 Q 함수를 학습하기 위해서는 많은 시간을 학습에 투자해야 하며,환경에서 제공되는 과도한 환경 상태 정보에 따라 학습이 잘 이루어지지 않거나,잘못
된 목표로 학습이 진행되는 경우가 발생하였다. 이러한 문제점을 극복하기 위해 Q 함수를 심층신경망으로 구성하여 학습을 진행하는 연구 방법들이 연구되었고,이 방법들을 통해
Q 함수의 학습효율 및 예측 정확도 성능을 높여 보다 효과적인 행동 제어 기반의 최적화 기계학습 알고리즘을 제공할 수 있게 되었다. 구글의 딥마인드는 DQN을 처음으로 소개
하였고,우리가 잘 알고 있는 Atari 게임부터 AlphaGo(2016)를 거쳐 현재 AlphaStar(2019)와 같은 고성능 게이밍 환경을 이용하여 강화학습의 성과를 이루어 내고 있다
...................(계속)
☞ 자세한 내용은 내용바로가기 또는 첨부파일을 이용하시기 바랍니다.
관련정보
지식
동향